





Python
未读
数据的采集与处理-网络爬虫
网络爬虫 网络爬虫(又称为网页蜘蛛,网络机器人),英文名叫 Web crawler 或 Spider。是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。它是一种自动化抓取互联网信息的程序,也是搜索引擎的核心组成部分。网络爬虫可以根据指定的规则,从互联网上下载网页、图片、视频等内容,并抽取






Python
未读
计算机解决问题的过程
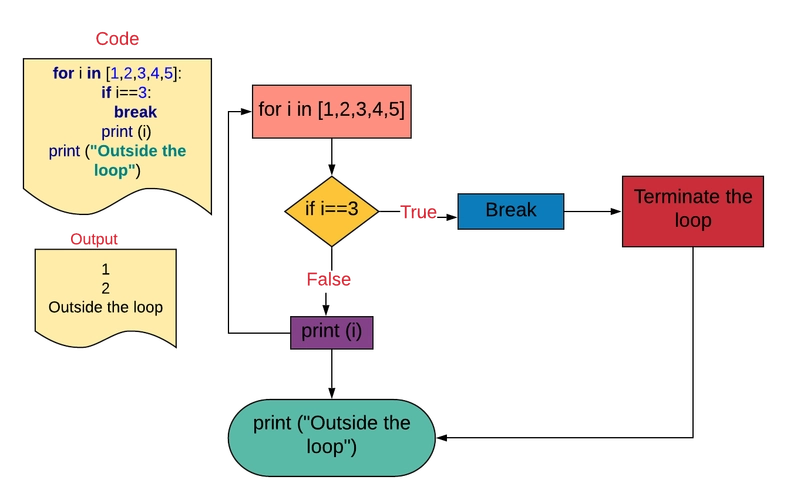
计算机解决问题的过程 分析问题、设计算法、编写程序、调试运行、检测结果 活动:贴春联 运行以下代码,对比用计算机贴春联和生活中贴春联的差异 Python程序运行调试方法参见:

在VScode中使用Python
安装扩展 点击左侧扩展按钮,在搜索框中输入Python并搜索 新建文件 在启动界面中单击新建文件,在新建文件类型列表中选择Python文件 在创建的文件中编写代码





