





数据可视化-词云
数据可视化
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息,发展到后来,应用3D图形来展示,使得数据更加的生动与形象。信息的质量很大程度上依赖于其表达方式,同样的,对数据进行数据分析后,结果可视化可以帮助用户更好地理解数据信息,挖掘数据价值。数据可视化的本质就是视觉对话,数据可视化将数据分析技术与图形技术结合,清晰有效地将分析结果信息进行解读和传达。数据和数据可视化是相辅相成的,数据赋予可视化以依据,可视化增加数据的灵活性。
词云
“词云”这个概念由美国西北大学新闻学副教授、新媒体专业主任里奇·戈登(Rich Gordon)于提出,词云是一种可视化描绘单词或词语出现在文本数据中频率的方式,它主要是由随机分布在词云图的单词或词语构成,出现频率较高的单词或词语则会以较大的形式呈现出来,而频率越低的单词或词语则会以较小的形式呈现。词云图过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。

Python词云库
wordcloud库不是python内置库,需要使用pip命令安装。如果使用的其他Python环境,安装方法可能不同。
官方文档:WordCloud for Python documentation
安装词云库
按Win+R键,输入cmd确定,打开命令提示符。输入以下命令安装:
pip install wordcloud默认源安装可能会比较慢,可以指定清华大学镜像安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple wordcloud使用词云库
先创建词云对象,然后向词云对象中加载文本(默认通过空格分词),最后输出词云图片。
from wordcloud import WordCloud #导入词云库
w=WordCloud(background_color='white') #创建词云对象,设置背景为白色
f = open("youth.txt", encoding='utf-8').read() #打开文本,文件要和代码在同一个文件夹
w.generate(f) #用文本创建词云
w.to_file("mywordcloud.png") #输出词云为图片文件,文件生成在代码所在文件夹配置词云对象
默认的词云对象风格比较单调,在创建词云对象时可以通过参数来设置词云的风格。
w=WordCloud([参数]) 词云创建时可以设置参数,多个参数使用逗号分割
样例代码:
w = WordCloud(
width=1920, #设置宽度为1920px
height=1080, #设置图片长宽为1080px
background_color='white', #设置背景颜色为白色
font_path='C:/Windows/Fonts/msyh.ttc', #设置字体为微软雅黑
max_words=300, #设置词汇最大数量为300
)任务一:生成词云
利用附件中的文本生成一个英文词云图,尝试通过参数设置进行美化,将词云图片提交给老师。
附件: English Text.zip
中文词云
请观察下列样例文本,字词的分隔方式和英文文本有什么区别。
这是一段样例中文文本,床前明月光,疑是地上霜。举头望明月,低头思故乡。
This is a sample English text. And as we walk, we must make the pledge that we shall always march ahead.
wordcloud 默认会以空格或标点为分隔符对目标文本进行分词处理。所以中文文本制作词云之前需要进行分词的处理。
JIEBA库
jieba库是Python 一个重要的第三方中文分词函数库,但需要用户自行安装。它分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组;除此之外,jieba 库还提供了增加自定义中文单词的功能。
安装JIEBA库
按Win+R键,输入cmd确定,打开命令提示符。输入以下命令安装:
pip install jieba默认源安装可能会比较慢,可以指定清华大学镜像安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba使用JIEBA库
import jieba #导入JIEBA库
f = open("月亮古诗.txt", encoding='utf-8').read() #打开中文文本,文件要和代码在同一个文件夹
txt=jieba.cut(f) #使用cut函数分词,得到列表
txt= " ".join(txt) #join()方法将列表中的元素用指定的空格连接JIEBA库函数功能
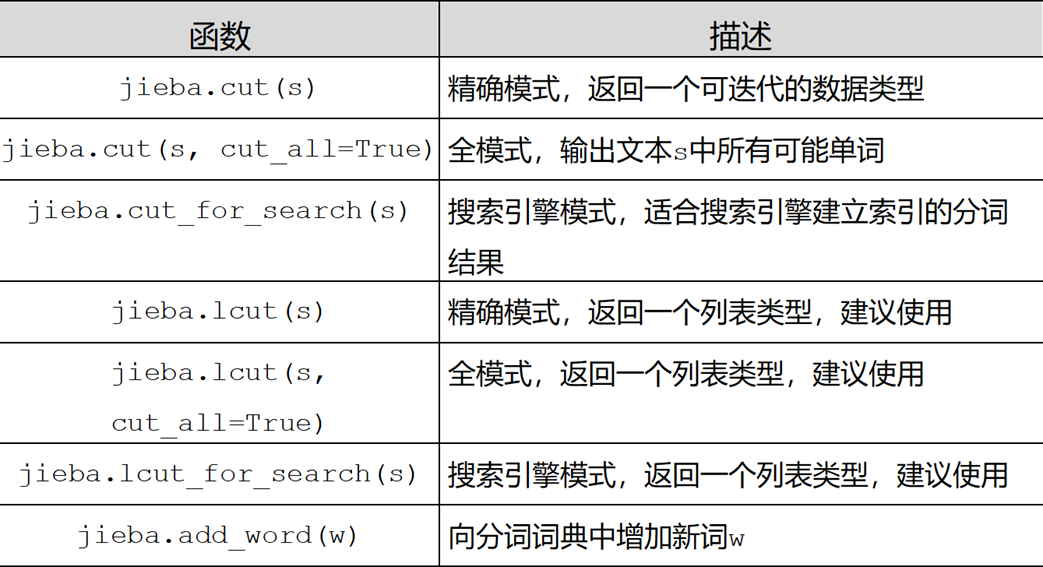
任务二:中文词云
分析JIEBA库的使用方法,将JIEBA代码插入到词云代码适当的位置后,利用附件中的中文文本生成一个中文词云图,将词云图片提交给老师。
提示:使用中文生成词云,在创建词云对象时,必须设置字体参数为一个中文字体文件!
附件:
文本 中文文本.zip
Mask参数
通过使用wordcloud函数的mask参数,可以让词云图变成指定图片的形状。

mask参数接受的值为蒙版图像矩阵,需要用到numpy、Image这两个库来处理图片文件,方法如下:
from PIL import Image #导入Image库
import numpy as np #导入numpy库
img = np.array(Image.open('maskname.jpg')) #将一张图片处理为蒙版图像矩阵任务三:个性化词云
分析mask参数的用法,将图像处理代码插入到词云代码适当位置后,使用mask参数指定词云的形状,选择相同主题的文本和图片形状进行词云制作,并尝试修改各个属性达到满意的效果将至少生成2个词云文件提交给老师。
附件:mask图片包.zip







