




数据的采集与处理-网络爬虫
网络爬虫
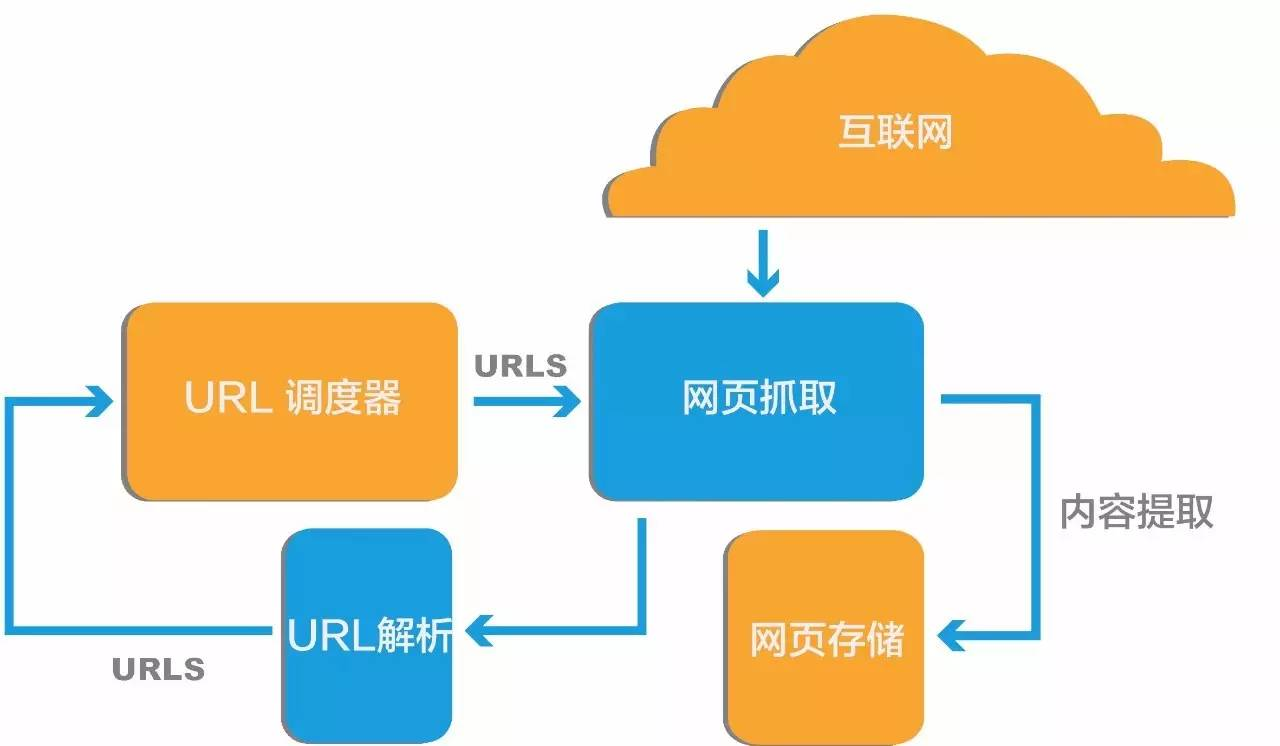
网络爬虫(又称为网页蜘蛛,网络机器人),英文名叫 Web crawler 或 Spider。是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。它是一种自动化抓取互联网信息的程序,也是搜索引擎的核心组成部分。网络爬虫可以根据指定的规则,从互联网上下载网页、图片、视频等内容,并抽取其中的有用信息进行处理。网络爬虫的工作流程包括获取网页源代码、解析网页内容、存储数据等步骤。
URL
网络链接,即根据统一资源定位符(URL,uniform resource location),统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息是指出文件的位置以及浏览器应该怎么处理它。它最初是由蒂姆·伯纳斯·李发明用来作为万维网的地址,现在它已经被万维网联盟编制为互联网标准了。
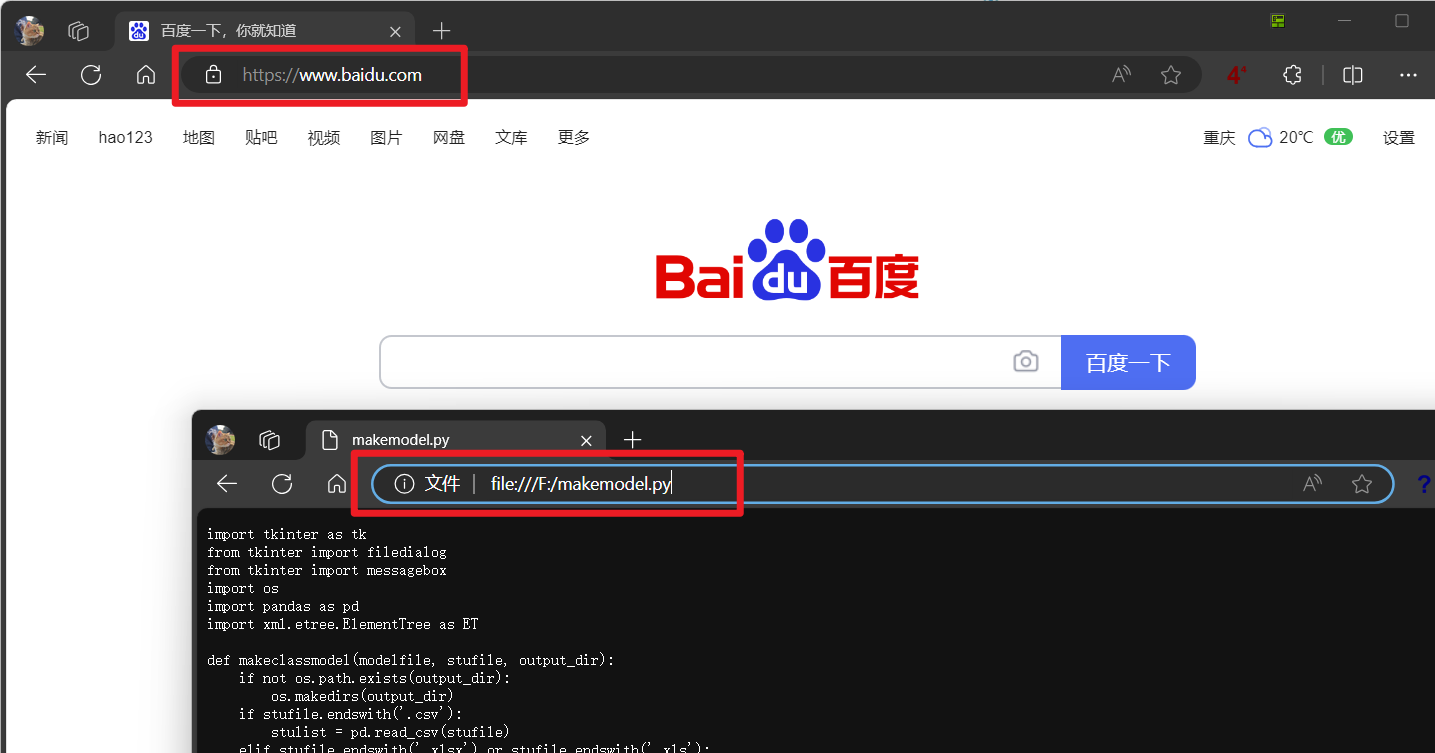
URL格式:
协议类型://服务器地址或IP地址[:端口号]/路径/文件名[参数=值][锚点]
例如本页面的URL地址:https://class.cqljxdfz.com/archives/1711605416392
1、协议部分
如HTTP协议,即超文本传输协议,该协议支持简单的请求和响应会话,对于Web服务器,最常用的便是HTTP协议。注意:除了HTTP协议以外,还有File、Ftp协议等。
2、服务器域名或IP地址部分
Web应用是运行于Web服务器端的,而IP地址指的就是服务器在网络中的地址,不过现在基本所有的网站所使用的都是由dns域名系统所分配的域名。
3、端口号
端口是服务器用于内外部通信的通道,当用户访问服务器时必须从要求的端口访问才能正常打开网页。
4、路径
由零或多个“/”符号隔开的字符串,一般用来表示主机上的一个目录或文件地址。一般网页的所有资源不会只保存在同一级目录中。
5、文件名部分
从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
6、参数
用于指定特殊参数的可选项,有服务器端程序自行解释。可选,用于给动态网页(如使用CGI、ISAPI、PHP/JSP/ASP/ASP.NET等技术制作的网页)传递参数,可有多个参数,以“?”开始,用“&”符号隔开,每个参数的名和值用“=”符号隔开。
7、锚点部分
从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
常见网络协议:
file 资源是本地计算机上的文件。格式 file:///,注意后边应是三个斜杠。
ftp 通过FTP访问资源。格式 FTP://
gopher 通过Gopher协议访问该资源
http 通过HTTP访问该资源。 格式 HTTP://
https 通过安全的HTTPS访问该资源。格式 HTTPS://
mailto 资源为电子邮件地址,通过SMTP访问。格式 mailto:
网页
网页是构成网站的基本元素,是承载各种网站应用的媒介。网页是一个包含HTML标签的纯文本文件,它可以存放在世界某个角落的某一台计算机中,是万维网中的一“页”,是超文本标记语言格式。网页通常用图像文件来提供图片。网页要通过网页浏览器来阅读。
HTML
HTML语法官方文档:Html 官方文档 |w3cschool
HTML教程:HTML 系列教程 (w3school.com.cn)
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言,文件扩展名为.html或.htm。
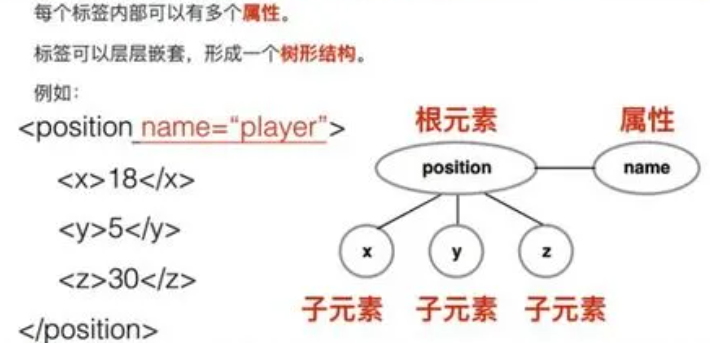
您可以使用 HTML 来建立自己的 WEB 站点,HTML 运行在浏览器上,由浏览器来解析。
一个基础的网页示例:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title name='IT class'>信息技术学习(class.cqljxdfz.com)</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
<h1>我的第二个标题</h1>
</body>
</html>获取网页:Requests库

官方文档:HTTP for Humans™ — Requests documentation
官方中文文档(非最新版本):让 HTTP 服务人类 — Requests 2.18.1 文档
Requests库是一个开源的为人类设计的简单而优雅的 HTTP 库,用于发送HTTP/HTTPS请求并处理响应。它的设计理念是“人类可读”(Human-friendly),提供简单易用的API,使发送HTTP请求更加直观和方便。Requests支持多种HTTP方法,如GET、POST、PUT、DELETE等,还支持基于会话的请求、自动处理Cookies、自动处理重定向、请求和响应数据的编码(如JSON和XML),并且可以自动验证SSL证书。
Requests库还支持发送文件、自动确定响应内容的编码、国际化URL和POST数据的自动编码等功能。它的底层实现是基于urllib3,并且文档齐全,包括中文文档,适合各种级别的用户使用。
安装requests库
按Win+R键,输入cmd确定,打开命令提示符。输入以下命令安装:
pip install requests默认源安装可能会比较慢,可以指定清华大学镜像安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests使用requests获取网页
requests.get()函数,返回一个响应对象,即我们向服务器发送请求之后,服务器返回给我们的内容,其中就包含了网页信息。根据HTTP协议,发送请求时可以附带多个参数,其中最重要的是headers参数,它包含客户端环境的信息,如浏览器类型、操作系统、接受的内容类型,等等。
response = requests.get(
url, #指定请求的URL地址,参数是一个字符串
[headers = myheaders] #可选参数,设置HTTP请求头部,headers是一个关键字参数,通过赋值符号传递。设置该参数可以让服务器认为是一个普通的浏览器访问,从而降低被识别为机器的概率,以免被服务器拒绝响应
)
html_content = response.text # 获取 HTML 文档内容response 是服务器对请求的响应对象,response.text 属性则是获取响应内容的方式之一,返回的是字符串形式的 HTML 文档内容。
实例:获取学习网站首页
#调用request库
import requests
#设置网页链接及请求头部参数
url = 'https://class.cqljxdfz.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}
#向服务器发送URL请求并获取网页文本
html = requests.get(url,headers=headers).text任务一:获取豆瓣电影网页
豆瓣电影TOP250的本地镜像URL:https://movie.cqljxdfz.com/douban/top250-1.html
1.使用requests库获取豆瓣电影的网页,并输出到屏幕上查看一下内容。
2.在网页中找到电影名称所在的标签。
解析网页:Beautiful Soup库

官方中文文档:Beautiful Soup 4.12.0 文档
BeautifulSoup库是由Leonard Richardson开发的一款Python库,用于从 HTML 和 XML 文件中提取数据。它提供了一种简单的方式来浏览、搜索和修改 HTML/XML 结构,使得从网页中提取特定信息变得更加容易。Beautiful Soup 可以处理不规范的标记,并将其转换为一个可以访问和操作的树形数据结构。
安装BeautifulSoup库
按Win+R键,输入cmd确定,打开命令提示符。输入以下命令安装:
pip install bs4默认源安装可能会比较慢,可以指定清华大学镜像安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bs4使用bs分析网页
1.初始化解析器
from bs4 import BeautifulSoup
# 初始化一个 BeautifulSoup 对象
soup = BeautifulSoup(html_doc, 'html.parser') # 加载网页文本,使用 html.parser 解析器2.查找标签
# 查找单个标签
tag = soup.find('tag_name') # 查找第一个指定名称tag_name的标签
# 查找单个标签并指定属性
tag = soup.find('tag_name',attrs={'att_name': 'att_value'}) # 查找第一个指定名称tag_name,并且att_name属性为att_value的标签
# 查找所有符合条件的标签
tags = soup.find_all('tag_name') # 查找所有指定名称tag_name的标签
# 查找所有符合条件的标签
tags = soup.find_all('tag_name',attrs={'att_name': 'att_value'}) # 查找所有指定名称tag_name,并且att_name属性为att_value的标签3.获取标签内容和属性
# 获取文本内容,tag只能为某一个标签对象,如果是find_all对象,则应使用循环遍历
text = tag.text
# 获取属性值
attribute_value = tag.get('attribute_name')实例:提取网页的标题信息
from bs4 import BeautifulSoup
#样例网页内容
html_doc='''<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title name='IT class'>信息技术学习(class.cqljxdfz.com)</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
<h1>我的第二个标题</h1>
</body>
</html>'''
#加载网页,初始化解析器,存放至soup变量
soup = BeautifulSoup(html_doc,'html.parser')
#查找第一个名为title的并且name属性为IT class的标签,并提取标签内容
title = soup.find('title',attrs={'name': 'IT class'}).text
print(title)
#查找所有名为h1的标签,并通过循环输出每个标签的内容
h1=soup.find_all('h1')
for i in h1:
print(i.text)以上实例输出内容为:
信息技术学习(class.cqljxdfz.com)
第一个要点
第二个要点任务二:提取网页中电影名称信息
提示代码
#在ol标签下查找所有名为li的标签,并通过循环输出每个电影名称标签的内容
movielist=soup.find('ol').find_all('li')
for name in movielist:
title = name.find('span',attrs={'class': 'title'}).text
print(title)1.使用Beautiful Soup库提取网页中所有电影的名。
2.尝试提取网页中所有电影的评分和短评的内容。
任务三:获取完整榜单
经过观察,豆瓣TOP250榜单翻页时,URL变化规律如下

为避免被豆瓣服务器ban掉,请使用学校镜像中的静态页面提取,URL地址规律如下:
https://movie.cqljxdfz.com/douban/top250-1.html
https://movie.cqljxdfz.com/douban/top250-26.html
……
https://movie.cqljxdfz.com/douban/top250-225.html尝试使用循环来把所有页面中的电影名称提取出来






