





数据编码
文字的编码
目前的文字编码标准主要有 ASCII、GB2312、GBK、Unicode等。ASCII 编码是最简单的西文编码方案。GB2312、GBK、GB18030 是汉字字符编码方案的国家标准。ISO/IEC 10646 和 Unicode 都是全球字符编码的国际标准 。
ASCII编码
美国的标准协会在1967年制定出了ASCII编码,到目前为止共定义了128个字符。其中前 32 个(0~31)是不可见的控制字符,32~126 是可见字符,127 是 DELETE 命令(键盘上的 DEL 键)。
American Standard Code for Information Interchange 美国信息交换标准代码
 汉字编码
汉字编码
GB2312-80 标准
GB2312-80 是 1980 年制定的中国汉字编码国家标准。共收录 7445 个字符,其中汉字 6763 个。GB2312 兼容标准 ASCII码,采用扩展 ASCII 码的编码空间进行编码,一个汉字占用两个字节,每个字节的最高位为 1。具体办法是:收集了 7445 个字符组成 94*94 的方阵,每一行称为一个“区”,每一列称为一个“位”,区号位号的范围均为 01-94,区号和位号组成的代码称为“区位码”。区位输入法就是通过输入区位码实现汉字输入的。将区号和位号分别加上 20H,得到的 4 位十六进制整数称为国标码,编码范围为 0x2121~0x7E7E。为了兼容标准 ASCII 码,给国标码的每个字节加 80H,形成的编码称为机内码,简称内码,是汉字在机器中实际的存储代码GB2312-80 标准的内码范围是 0xA1A1~0xFEFE。
GBK 编码标准
《汉字内码扩展规范》(GBK) 于1995年制定,兼容GB2312、GB13000-1、BIG5 编码中的所有汉字,使用双字节编码,编码空间为 0x8140~0xFEFE,共有 23940 个码位,其中 GBK1 区和 GBK2 区也是 GB2312 的编码范围。收录了 21003 个汉字。GBK向下与 GB 2312 编码兼容,向上支持 ISO 10646.1国际标准,是前者向后者过渡过程中的一个承上启下的产物。ISO 10646 是国际标准化组织ISO 公布的一个编码标准,即 Universal Multilpe-Octet Coded Character Set(简称UCS),大陆译为《通用多八位编码字符集》,台湾译为《广用多八位元编码字元集》,它与 Unicode 组织的Unicode编码完全兼容。ISO 10646.1 是该标准的第一部分《体系结构与基本多文种平面》。我国 1993 年以 GB 13000.1 国家标准的形式予以认可(即 GB 13000.1 等同于 ISO 10646.1)。
GB18030编码标准
国家标准GB18030-2000《信息交换用汉字编码字符集基本集的补充》是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。GB18030-2000编码标准是由信息产业部和国家质量技术监督局在2000年 3月17日联合发布的,并且将作为一项国家标准在2001年的1月正式强制执行。GB18030-2005《信息技术中文编码字符集》是我国制订的以汉字为主并包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准,其中收入汉字70000余个。

任务一:编码查看工具
试一试用GB2312编码查看以下4个编码:B9B2 CDAC BDF8 B2BD

图像编码
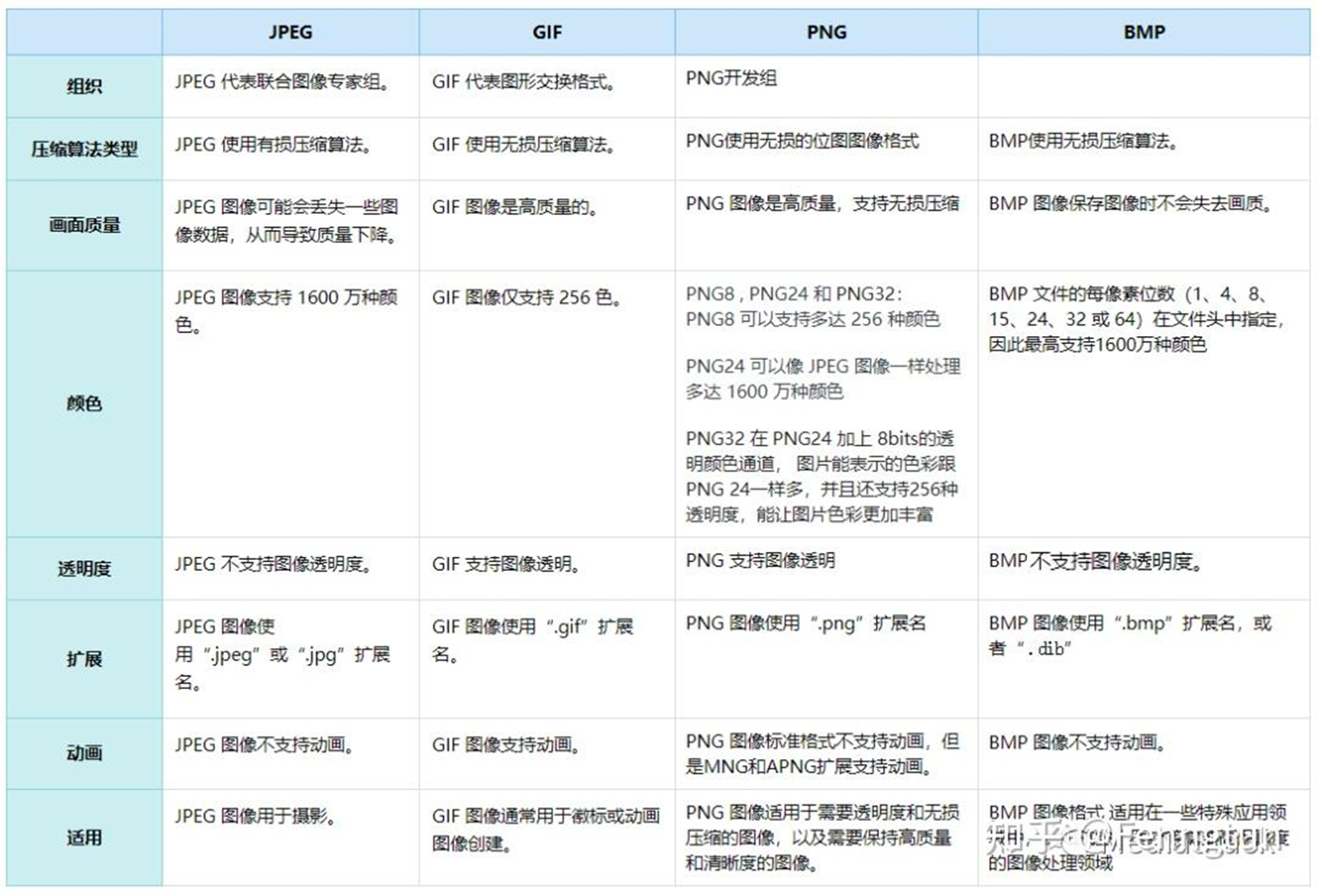
位图BMP格式
BMP图像是一种光栅图像(包含像素数据而不是矢量图像)格式。BMP图像的每个像素由单个位或一组位定义。自个人计算早期就已存在。它是一种无损格式,意味着保存图像时不会丢失任何信息。但是,它也是一种非常大的格式,因此难以存储和传输。
其他图像格式对比
音频编码
自然界中的声音非常复杂,波形极其复杂,通常我们采用的是脉冲代码调制编码,即PCM编码。PCM通过抽样、量化、编码三个步骤将连续变化的模拟信号转换为数字编码。
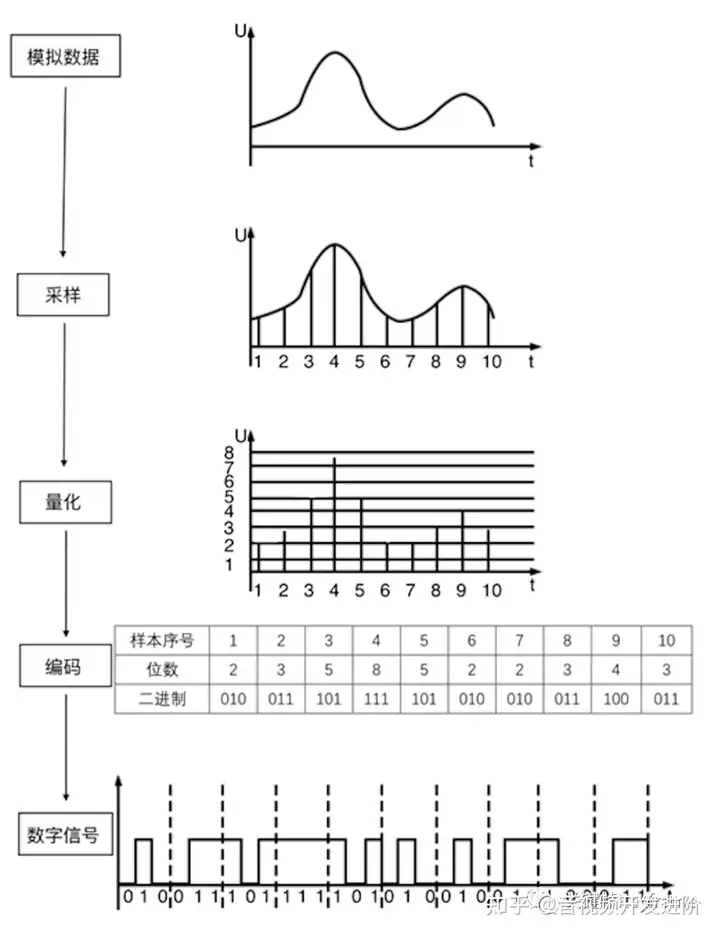
模拟信号转换数字信号的步骤
常见的音频格式:
PCM,无压缩。一种将模拟信号的数字化方法,无损编码。
WAV,无压缩。有多种实现方式,但是都不会进行压缩操作。其中一种实现就是在 PCM 数据格式的前面加上 44 字节,分别用来描述 PCM 的采样率、声道数、数据格式等信息。音质非常好,大量软件都支持。
MP3,有损压缩。音质在 128 Kbps 以上表现还不错,压缩比比较高,大量软件和硬件都支持,兼容性好。
AAC,有损压缩。在小于 128 Kbps 的码率下表现优异,并且多用于视频中的音频编码。
任务二:查看音频编码
下载声音文件,解压缩后在音频编辑软件(Adobe Audition)中查看模拟信号转数字信号的采样痕迹:清脆的铃声.zip
视频编码
存储单位
比特(bit,Binary digit),二进制数的一位所包含的信息就是一比特,为信息量的最小单位,如二进制数0100就是4比特;
字节(Byte),每8个位(bit,简写为b)组成一个字节(Byte,简写为B)。
PB、EB、ZB、YB 、NB、DB都是存储单位。
1PB(Petabyte,千万亿字节,拍字节)=1024TB= 2^50 B;
1EB(Exabyte,百亿亿字节,艾字节)=1024PB= 2^60 B;
1ZB(Zettabyte,十万亿亿字节,泽字节)= 1024EB= 2^70 B;
1YB(Yottabyte,一亿亿亿字节,尧字节)= 1024ZB= 2^80 B;
1BB(Brontobyte,一千亿亿亿字节)= 1024YB= 2^90 B;
1NB(NonaByte,一百万亿亿亿字节) = 1024BB = 2^100 B;
1DB(DoggaByte,十亿亿亿亿字节) = 1024 NB = 2^110 B。

字
在计算机中,一串数码作为一个整体来处理或运算的,称为一个计算机字,简称字。字通常分为若干个字节(每个字节一般是8位)。在存储器中,通常每个单元存储一个字,因此每个字都是可以寻址的。字的长度用位数来表示。
在计算机的运算器、控制器中,通常都是以字为单位进行传送的。字出现在不同的地址其含义是不相同。例如,送往控制器去的字是指令,而送往运算器去的字就是一个数。
字长
计算机的每个字所包含的位数称为字长。根据计算机的不同,字长有固定的和可变的两种。固定字长,即字长度不论什么情况都是固定不变的;可变字长,则在一定范围内,其长度是可变的。
计算的字长是指它一次可处理的二进制数字的数目。计算机处理数据的速率,自然和它一次能加工的位数以及进行运算的快慢有关。如果一台计算机的字长是另一台计算机的两倍,即使两台计算机的速度相同,在相同的时间内,前者能做的工作是后者的两倍。
例如:32位处理器一次可以处理的数据最大长度就是32bit,4Byte,4个字节,它的字长就是32。目前主流的处理器为64位,在数据中心或者高性能计算领域还有更大位宽的处理器。
拓展阅读
二进制其实不存在
你可能认为计算机中的数据就是「01」二进制,但是实际上计算机中并没有二进制,即便我们知道所有的内容都是存储在硬盘中,但是你把它拆开可找不到里面有任何「0101」的数字,里面也只有盘片、磁道。就算我们放大了去看盘片,也只有凹凸不平的盘面,凸起的地方是被磁化过的,凹进去的地方是没有被磁化的;只是我们给凸起的地方取了个名字叫数字「1」,凹进的地方取名叫数字「0」。
同样内存里你也找不到二进制数字,内存放大了看就是一堆电容组,内存单元存储的是「0」还是「1」取决于电容是否有电荷,有电荷我们认为他是「1」,无电荷认为他是「0」。但是电容是会放电的,时间一长,代表「1」的电容会放电,代表「0」的电容会吸电,这也是我们内存不能断电的原因,需要定期对电容进行充电,保证「1」的电容电量有电。
再说显示器,这个大家感受是最直接的,你透过显示器看到的美女画皮、日月山川,其实就是一个个不同颜色的发光二极管发出强弱不一的光点,显示器就是一群发光二极管组成的矩阵,其中每一个二极管可以被称为一个像素,「1」表示亮,「0」表示灭,而我们平时能看到五彩的颜色,是把三种颜色(红绿蓝三原色)的发光二极管做到了一起。那对于一个ASCII编码「65」最后又怎么显示成「A」的呢?这就是显卡的功劳,显卡中存储了每一个字符的图形数据(也称字形码),将二维矩阵的图形数据传给显示器成像。

参考资料:一文读懂字符编码






