





Python修改极域班级模型
在极域软件中修改每台电脑的学生姓名需要在连线状态下逐个修改,十分不便。

经过分析,极域的班级模型文件“.cls”实则为xml文件格式,其中学生姓名存储在name标签下,将其改为学生的班级序号即可作为班级模型的模板文件。
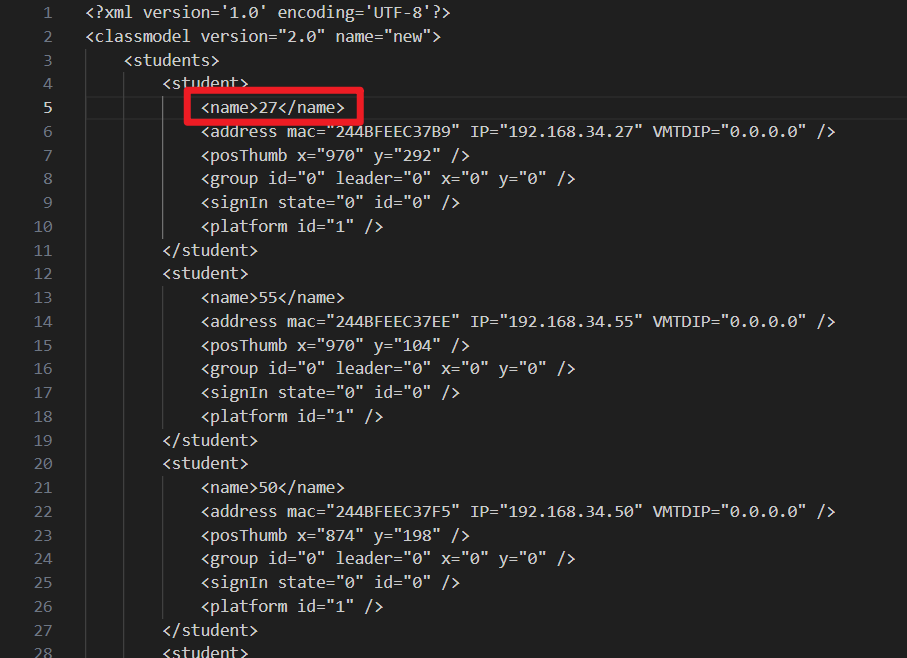
可以使用Python中的多种xml解析库来处理班级模型文件,下面的代码中将使用标准库中的xml处理模块:ElementTree API,一个简单而轻量级的XML处理器。
记录学生信息的Excel名单应至少包含3列,内容必须依次为班级、序号、姓名,首行必须有标题,内容不限。
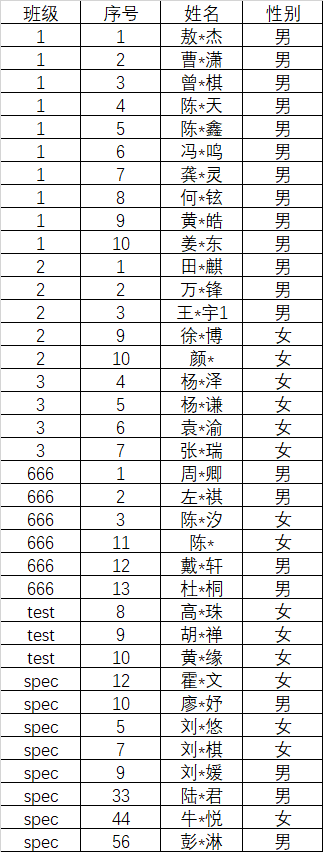
通过pandas库对表格进行读取,兼容xls、xlsx、csv格式,需要在Python环境中安装相应库。参考命令:
pip install pandas xlrd以下程序中通过定义makeclassmodel函数实现以班级为单位将学生姓名按照序号填充至班级模型中,超过班级模型内序号范围的学生将跳过。两个参数分别为班级模型文件和学生名单。学生名单支持xls、xlsx、csv格式。按"class+班级名.cls"格式生成班级模型文件。
处理效果:
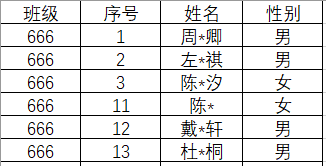 →
→
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: Mr.tang
@email: mrtang@cqljxdfz.com
@date: 20240410
@version: 1.0
@license: for free
Description:
本程序用于按学生名单生成极域班级模型。自动识别班级数量和名称,自动识别每班学生数量。将按"class+班级名.cls"格式生成文件。
极域班级模型文件要求:
在极域中把学生姓名改为学生的班级序号,即文件中的name标签,序号中小于10的数不需要用0填充。
学生名单文件要求:
1.支持xls、xlsx、csv格式
2.文件中至少包含3列,内容必须依次为班级、序号、姓名,必须包含标题,标题文字任意,如下所示
班级 | num. | 姓名
------- | --------- | ---------
1 | 1 | 敖*杰
------- | --------- | ---------
x班 | 2 | 曹*
------- | --------- | ---------
2 | 1 | 曾*棋
------- | --------- | ---------
……… | ……… | ………
3.名单可乱序、任意序号开始及不连号,班级名称可以自定义
4.所有序号中小于10的数不需要用0填充
changelog:
2024-04-11
修改班级遍历方式为分类后枚举,支持自定义班级名称并写入班级模型文件名
修改学生姓名定位方式为以序号匹配绝对定位,支持学生名单乱序、任意序号开始及不连号
changelog:
2024-04-12
修改表格前三列的标题,支持自定义标题内容
changelog:
2024-09-11
增加图形界面
"""
import tkinter as tk
from tkinter import filedialog
from tkinter import messagebox
import os
import pandas as pd
import xml.etree.ElementTree as ET
def makeclassmodel(modelfile, stufile, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
if stufile.endswith('.csv'):
stulist = pd.read_csv(stufile)
elif stufile.endswith('.xlsx') or stufile.endswith('.xls'):
stulist = pd.read_excel(stufile)
stulist.columns = ['班级', '序号', '姓名'] + stulist.columns[3:].tolist()
for classname, group in stulist.groupby('班级'):
tree = ET.parse(modelfile)
root = tree.getroot()
students = root.find('students').findall('student')
for student in students:
name_tag = student.find('name')
match = group[group['序号'] == int(name_tag.text)]
if not match.empty:
name_tag.text = match['姓名'].values[0]
output_file_path = os.path.join(output_dir, f'class{classname}.cls')
tree.write(output_file_path, xml_declaration=True, encoding='UTF-8')
messagebox.showinfo("完成", "所有班级模型文件已生成。")
def browse_file(entry):
filename = filedialog.askopenfilename()
entry.delete(0, tk.END)
entry.insert(0, filename)
def browse_folder(entry):
foldername = filedialog.askdirectory()
entry.delete(0, tk.END)
entry.insert(0, foldername)
root = tk.Tk()
root.title("班级模型文件生成器")
frame = tk.Frame(root)
frame.pack(padx=10, pady=10)
model_label = tk.Label(frame, text="模型文件路径:")
model_label.pack()
model_entry = tk.Entry(frame, width=50)
model_entry.pack()
model_button = tk.Button(frame, text="浏览...", command=lambda: browse_file(model_entry))
model_button.pack()
student_label = tk.Label(frame, text="学生名单文件路径:")
student_label.pack()
student_entry = tk.Entry(frame, width=50)
student_entry.pack()
student_button = tk.Button(frame, text="浏览...", command=lambda: browse_file(student_entry))
student_button.pack()
output_label = tk.Label(frame, text="输出目录:")
output_label.pack()
output_entry = tk.Entry(frame, width=50)
output_entry.pack()
output_button = tk.Button(frame, text="浏览...", command=lambda: browse_folder(output_entry))
output_button.pack()
generate_button = tk.Button(frame, text="生成班级模型文件", command=lambda: makeclassmodel(model_entry.get(), student_entry.get(), output_entry.get()))
generate_button.pack(pady=10)
root.mainloop()
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 信息技术学习






